Monolithic Architecture
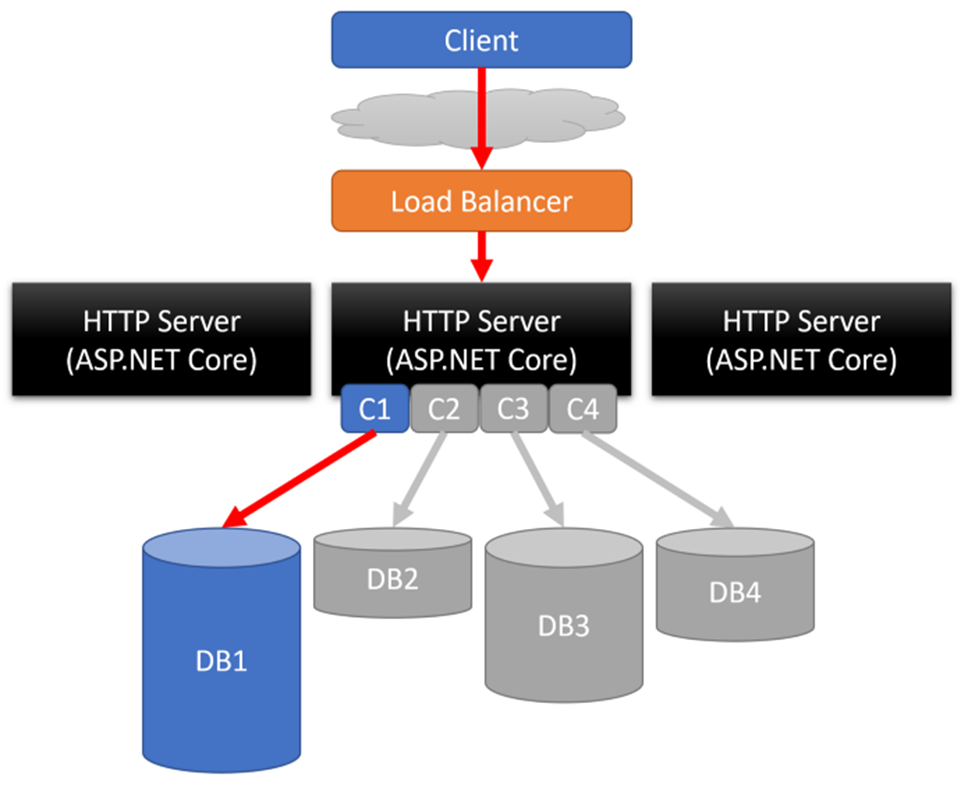
Before the advent of Microservices architecture, Monolithic architecture was predominant across the web. As seen from the picture above, lets us assume that this is the Monolith application that runs on a physical server on-premised. It has 3 servers and all of them have static ips and the requests are routed to them using a load balancer. The IP of these 3 servers are stored in a config file usually and are read by the load balancer. In this case, there is no need of a Service Registry as the IP addresses of these 3 APP servers are fixed and wont change.
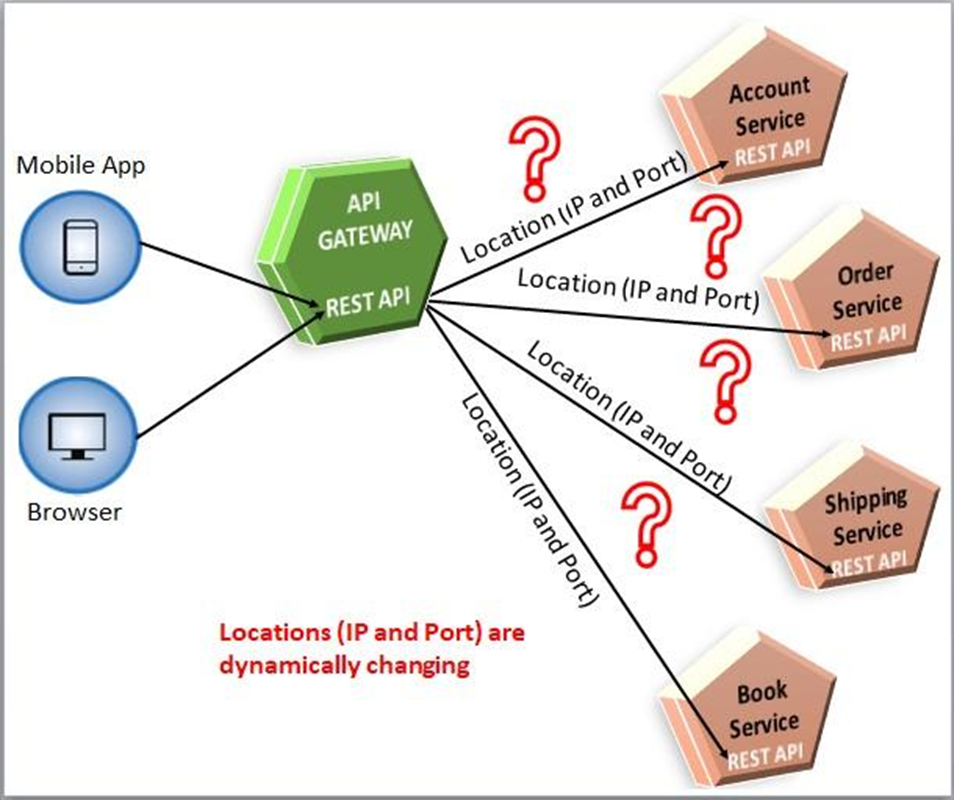
Microservices Architecture
In case of a micro-service architecture which is deployed in the cloud, there will be lot of microservice components for different service. Every microservice can scale differently based on the demands. The Order service might have 4 or 5 instances and Billing Service might have 2 or 3 instances running. With each instance having dynamic network address because of multiple factors like Autoscaling, Upgrade, Failure, Deployments etc, it is extremely difficult to locate these services and communicate with them.
This problem leads to the solution in the form of a design pattern called Service Discovery.
What is Service Discovery
Service Discovery is a design pattern by which the Client or the API Gateways discover about the network info (IP address and port) of the Server through an important component called Service Registry or Discovery Server. The Service Registry keeps track of the entire individual microservices in the architecture and stores the IP address / Port of those in its database. Every time a service scales up or down, it will send heart-beat to the discovery service and it will update its database accordingly. The discovery server / Registry also groups the instances of the each service accordingly.
There are two types of Service Discovery as follows
- Client-Side service discovery

In the Client-side service discovery pattern, the client is responsible for discovery the network address of the service instances and load balance the requests to the instances of the same service. The client will query the Service Registry to get the list of available instances for the particular service and then use an efficient load balancing algorithm to select one of the instances and send request to it.
Netflix OSS is an example for Client Side Service Discovery. Eureka Server is the Service Registry and Netflix Ribbon is a of client-side load balancer. Ribbon is a client-side load balancer that gives you a lot of control over the behavior of HTTP and TCP clients. Eg: When a microservice A talks to microservice B using Feign Client, the service A contacts Eureka to get the information about all the instances of Service B. Then the Ribbon load balancer on Service A will find the best instance of Service B to send the request.
Advantages:
- This pattern is quite simple and straight forward to implement as the client only needs to communicate with the Service Registry
- Client can have its own Load Balancing algorithm like Round Robin or Consistent Hashing etc
Drawback:
- The Service Discovery logic is tightly coupled with the client and hence it is difficult if we have different types of clients and frameworks
2. Server-side service discovery

This is the most widely used pattern for Service Discovery. Here the client makes call to the Load Balancer which then queries the Service Registry to discover the instances and query one of them. The load balancing logic now stays inside the Load Balancer component and this is common to any client or frameworks that requests it. Load Balancer component is the only change when compared to the Client Side Service Discovery
The AWS Elastic Load Balancer (ELB) is an example of a server-side discovery pattern. The EC2 servers or ECS containers will register their network information to the ELB which act as both the Router and the Service Registry. When a request reaches ELB, it can route to the specific instances after picking the best match through the algorithm.
Advantages:
- The discovery information is abstracted de-couple from the clients
- Implementation is quite simple for the client side as it just needs to call the load balancer DNS
Drawbacks:
- For a non-cloud environment, the Router or Load Balancer is an extra physical component to be maintained in terms of configuration, replication, availability etc.
- More network hops are required than when using the Client Side Discovery Pattern
Common Service Registry / Discovery Frameworks
The most widely used Service Discovery frameworks are
- Netflix OSS — This is widely used for Spring framework applications that are deployed in the cloud. Eureka is the Service Registry (Discovery Server) and all other microservices components are the clients of Eureka.
- etcd — This is ahighly available, distributed, consistent, key‑value store that is used for shared configuration and service discovery which is use dby Kubernetes and Cloud Foundary.
- consul — Hashicorp consul isthe one stop solution for microservices (self) registration, discovery, health checks, key-value store and load balancing. It is one of the powerful frameworks
Moreover, every cloud provider has its own service discovery as well. I will leave it to you to explore in-depth on Service Discovery.
In this article, we saw what is the need for Service Discovery in the modern microservices architecture and also the various types of such patterns.
I work as a freelance Architect at Ontoborn, who are experts in putting together a team needed for building your product. This article was originally published on my personal blog.